Investigadores de Apple dicen haber logrado un avance clave en el despliegue de grandes modelos de lenguaje (LLM) en iPhones y otros dispositivos Apple con memoria limitada, lo que se convierte en la piedra angular para la llegada de modelos de inteligencia artificial generativa y el sueño de un Siri realmente útil y poderoso al iPhone, al iPad, al Apple Watch y, claro, a las Apple Vision Pro.
En un documento llamado LLM in a flash: Efficient Large Language Model Inference with Limited Memory, los investigadores utilizan 2 técnicas que minimizan las transferencia de datos requerida para el funcionamiento de los LLMs, maximizando el rendimiento de las memoria flash existentes en los dispositivos móviles de la compañía.
El primero lo describen como Ventaneo y lo asemejan a un método de reciclaje en el que en vez de cargar nuevos datos cada vez, el modelo de IA reutiliza algunos de los datos que ya ha procesado. Esto reduce la necesidad de recuperar la memoria constantemente, acelerando el proceso y volviéndolo más “suave”.
El segundo, denominado Agrupación de Filas y Columnas es parecido a leer un libro en trozos más grandes en lugar de una palabra a la vez. Al agrupar los datos de manera más eficiente, se pueden leer más rápido desde la memoria flash, lo que acelera la capacidad de la IA para entender y generar lenguaje.
La combinación de estos métodos permite que los modelos de IA funcionen hasta el doble del tamaño de la memoria disponible del iPhone, aumentando entre 4x y 5x en la velocidad en los procesadores de la CPU y 20x a 25x (!!!!) en los procesadores gráficos (GPU).
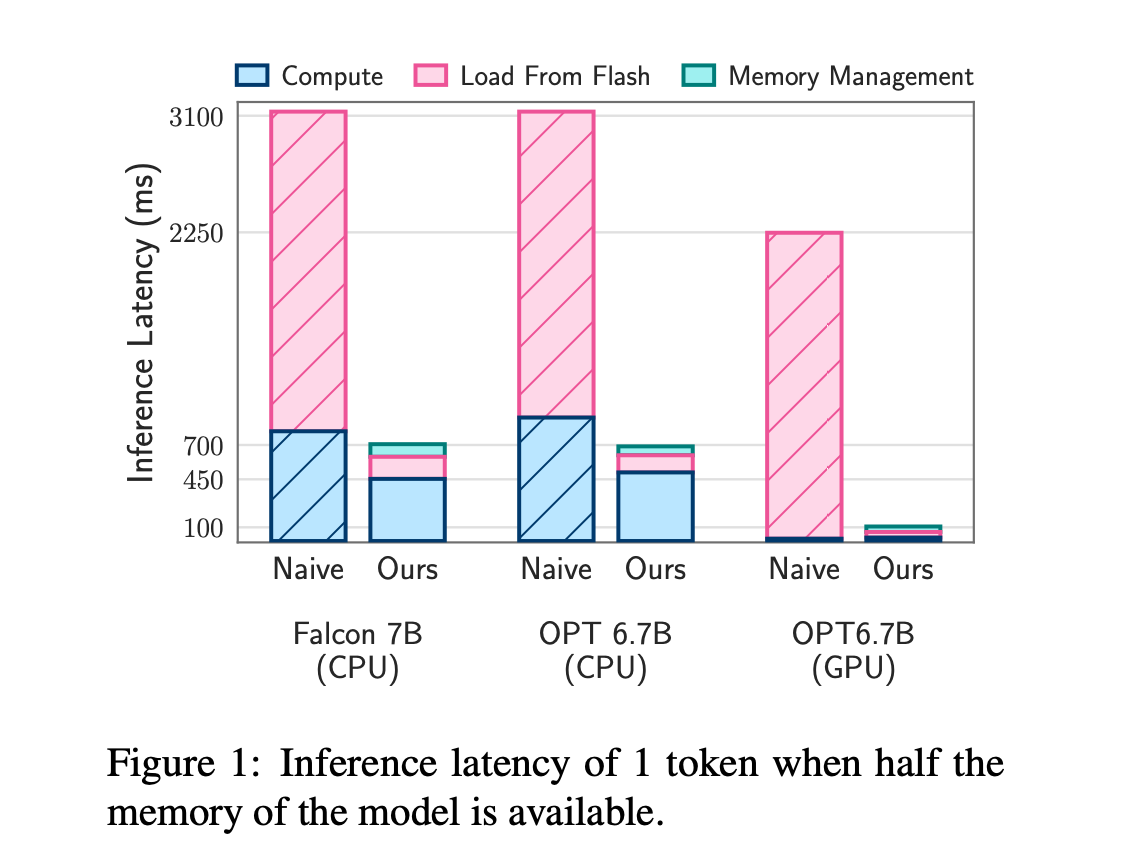
Estos avances abren nuevas posibilidades para futuros iPhones, como capacidades más avanzadas de Siri, traducción de idiomas en tiempo real y funciones impulsadas por la IA en fotografía y realidad aumentada. La tecnología también prepara el escenario para que los iPhones ejecuten complejos asistentes de IA y chatbots en el dispositivo, algo en lo que sabemos Apple está trabajando desde comienzo del año cuando GhatGPT cogió a todo el mundo por sorpresa.
El anuncio se une a la presentación de DATACOMP, un nuevo nuevo modelo multimodal (parecido a Gemini de Google) que combina varios tipos de datos -como imágenes y texto-, presentado por la compañía en conjunto con investigadores de la la Universidad de Washington y que contiene 12.800 millones de pares de imágenes y datos de texto de Common Crawl, con los que se pueden obtener mejores resultados que los obtenidos por los modelos de OpenAI
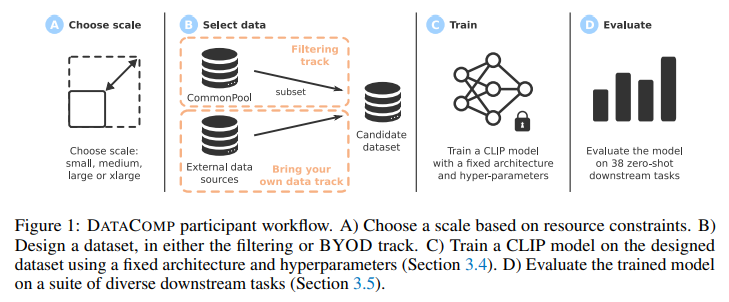
, han desempeñado un papel crucial en el avance de la inteligencia artificial. Estos conjuntos de datos permiten a los modelos de IA comprender y generar contenido en diferentes modalidades, lo que lleva a un progreso significativo en el reconocimiento de imágenes, la comprensión del lenguaje y las tareas intermodales. A medida que aumenta la necesidad de sistemas integrales de IA, explorar y aprovechar el potencial de los conjuntos de datos multimodales se ha vuelto esencial para superar los límites de las capacidades de aprendizaje automático. Investigadores de Apple y la Universidad de Washington han introducido DATACOMP, un centro de pruebas de conjuntos de datos multimodal que contiene 12.800 millones de pares de imágenes y datos de texto de Common Crawl.